 |
Version 10.0.2
|
|
Version 10.0.2
|
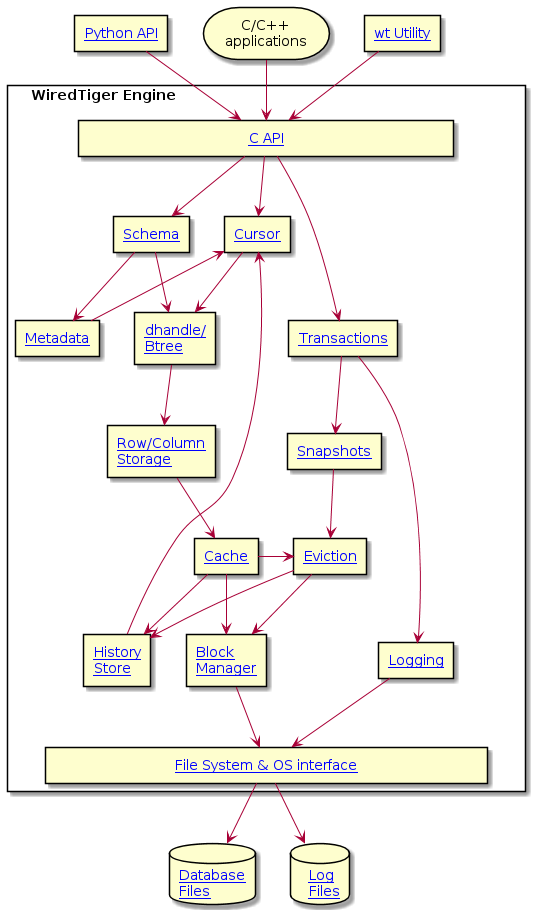 | Data Structures | Source Location |
|---|---|---|
| |
Caution: the Architecture Guide is not updated in lockstep with the code base and is not necessarily correct or complete for any specific release.
[This is all in terrible scattershot order and needs to be redone, but should probably finish a full draft before reworking it.]
In the timestamped world, the timing and ordering of commits is under application control. This requires that the application's time be made explicit, as opposed to being the same as wall-clock time as the application executes. Timestamps are points in application time. We shall refer to wall-clock time as the application executes as "execution time". Application time generally correlates with execution time, but there is not necessarily any close equivalence. We expect that the application's time generally rolls forward and that the range of application times that need to be considered at any point during execution is bounded. The design is not intended to provide arbitrary time travel; nor does it allow branching timelines, though there is some ability to rewind.
Thus, at any point during execution there is a window of application time under consideration, which this page will refer to as the "active time window". This window is divided into two parts: the stable portion, in which the composition of the data is fixed, further write operations are prohibited, and all updates are fully durable; and the unstable portion, in which changes to the data are still being accumulated, write operations are ongoing, and updates may be committed and even checkpointed but are not yet fully durable. Reading from the unstable portion of the time window is not prohibited, but if done incautiously can lead to data inconsistency.
The application controls the active time window by manipulating two global timestamps: the oldest timestamp and the stable timestamp. The oldest timestamp gives the earliest point in application time where the application can/will start new transactions reading. Attempting to read before this point is an application error. The stable timestamp defines the point that divides the stable part of the time window from the unstable part. The front/future end of the time window is represented by the latest timestamp that has been used so far; this is, however. not explicitly managed or tracked. The application is free to advance time by whatever jumps it wishes.
Internally, WiredTiger tracks an additional bound, the pinned timestamp: this is the minimum over the oldest timestamp and the read timestamps of all running transactions. This is the "real" lower bound of the active time window, used for all operations that involve dropping or garbage-collecting data that has aged out. This ensures that the application can update the oldest timestamp without compromising operations already in progress.
Within the active time window, each read or write operation (removes count as writes) is performed at some given application time. As always, operations are grouped into transactions, and in keeping with the principle that transactions are atomic, times are attached to transactions, both conceptually and in the API. Each transaction has a read timestamp, which is the application time used for read operations, and a commit timestamp, which is the application time used for write operations. (Prepared transactions also have a prepare timestamp and a durable timestamp, which are elaborations of the commit timestamp; see Prepared transactions.)
Each change to a given database item's value is thus associated with a timestamp. Consequently, values themselves are associated with ranges of time. These are called time windows, not to be confused with the overall active time window of the database. The value of a database item starts when it is first written (in application time) and stops when it is next overwritten or removed. For any key present in the database there exists some sequence of values, each ranging from some start time to some stop time. This sequence is not necessarily contiguous (we do not treat "deleted" as a first class value; it is the absence of any other value) but the ranges are not permitted to overlap. Stop times are not inclusive; that is, when a value is overwritten its stop time is the same as the next value's start time, and reads at that time will yield the new value.
Because the portion of the active time window beyond the stable timestamp is considered provisional, it is discarded at key points: as part of recovery during startup, on shutdown, and also at any time the application wishes by calling WT_CONNECTION::rollback_to_stable.
Reads and writes continue to use the transaction system and in particular continue to operate using snapshot isolation. Reads will only see updates committed as of when the read transaction's snapshot was taken, regardless of the relationship of their commit timestamps to the read transaction's read timestamps. If reading beyond the stable timestamp, it is thus possible for one transaction to commit into another transaction's past, which violates consistency. Applications are expected to avoid this: in general all commit timestamps should be greater than all read timestamps, whether or not the dividing line is the same as the stable timestamp.
Non-timestamped reads in timestamped tables are permitted and proceed using ordinary snapshot isolation. This will always read the latest (in application time) committed values, and is therefore particularly susceptible to the inconsistency described in the preceding paragraph.
Non-timestamped writes in timestamped tables are also permitted. These create new values that begin at the beginning of time, retroactively (in execution time) replacing the entire prior value sequence once committed. (Snapshot isolation still applies, however: readers whose snapshots predate the non-timestamped write will continue to see the prior database state until they commit or get a new snapshot.)
Applications are expected to write the value sequence in order; that is, for each key in the database, every write should commit with a timestamp later than the latest existing timestamp for that key. This is currently not enforced; because MongoDB sometimes issues out of order updates, they must for the time being be handled.
Internally, timestamps are 64-bit unsigned integers, where 0 is reserved and increasing values correspond to later time. WiredTiger does not otherwise interpret the values of timestamps and they need not be real time or any clock time; sequential counters are perfectly satisfactory. The symbolic values WT_TS_NONE and WT_TS_MAX give 0 and the maximum possible timestamp, respectively.
Timestamps are exchanged with the application as strings, printed in hex without a leading 0x, and not as machine integers. (This is because they are handled using the configuration parameter system, which is string-based.)
Time windows are handled in memory using the struct type WT_TIME_WINDOW. This contains a start time and a stop time. The type actually has seven members:
start_ts (the start time)durable_start_ts (also the start time)start_txn (the transaction ID that committed the start of the value)stop_ts (the stop time)durable_stop_ts (also the stop time)stop_txn (the transaction ID that committed the stop/end of the value)prepare (the transaction-prepare state of the value)The prepare state is not properly speaking part of the time window, but it is also a property of the value and needs to be seen at most of the same points, and in particular also needs to be stored on disk along with the time information, so is kept in the time window structure for convenience.
The distinction between start_ts and durable_start_ts (and between stop_ts and durable_stop_ts) is the same as the distinction between a transaction's commit timestamp and its durable timestamp. See Prepared transactions.
Start times from at or before the pinned timestamp are all equivalent to "no start time" and can be represented as WT_TS_NONE. Similarly, transaction IDs from past write generations should not be retained and are represented as WT_TXN_NONE.
A value that is current and has not been overwritten or deleted has no stop time. This is represented with WT_TS_NONE in durable_stop_ts but WT_TS_MAX in stop_ts, and WT_TS_MAX in stop_txn.
The on-disk representation of the time window of the current on-disk value is an optional part of a value cell. Time windows that are not present are universal (no start time, no stop time); the stop times that mean "no stop time" are not stored. Other stop times are stored as differences from the start time to save space. Similarly, durable timestamps are stored as differences from their corresponding commit timestamps.
The on-disk representation of the time windows of older values are stored differently because those times are used for lookup purposes. See History Store.
Internal btree pages store aggregated time window information for the pages or sub-trees they reference. This represents, roughly, the union of the time intervals of the data items on the page. It is used to check if a particular timestamp interacts with any on-page items so the page can be skipped over if not. Aggregates are represented in memory by the WT_TIME_AGGREGATE structure, which contains the following elements:
newest_start_durable_ts (WT_TS_NONE if none)newest_stop_durable_ts (WT_TS_NONE if none, excludes any WT_TS_MAX)oldest_start_ts (WT_TS_NONE if none)newest_txn (WT_TXN_NONE if none, excludes any WT_TS_MAX)newest_stop_ts (WT_TS_MAX if none, including any WT_TS_MAX)newest_stop_txn (WT_TXN_MAX if none, including any WT_TXN_MAX)prepare (whether any prepared values are present)init_merge (flag for how the structure was initialized)These are self-descriptive, except for newest_txn, which is the maximum over the newest start transaction and newest stop transaction. The init_merge flag records whether the structure was initialized for aggregating time windows and merging with other time aggregates; this is used during reconciliation to accumulate the aggregate value to be stored in the parent. (Otherwise, it was not, and those operations are prohibited.)
Aggregation proceeds one time window at a time by taking maxima or minima of the various fields of the aggregate and their corresponding time window fields.
Note that a time aggregate that has been initialized for aggregation without having any time windows aggregated into it is not valid: oldest_start_ts starts at WT_TS_MAX, which is newer than the starting newest_stop_ts of WT_TS_NONE. Consequently, such time aggregates will fail verification. The proper aggregate for an empty page can be produced by aggregating in a single empty time window.
The on-disk representation of a time aggregate is packed into an address cell much as the on-disk representation of a time window is packed into a value cell.
In memory, when using timestamps, update structures are timestamped with the commit timestamp and durable timestamp. If a commit timestamp has been set when the update is created, it is applied immediately; otherwise it is set along with the durable timestamp at commit time. Non-prepared transactions are also permitted more than one commit timestamp; applying the commit timestamp to updates immediately enables that feature.
In general the commit time of uncommitted updates in the cache may not be known yet and consequently is not used to detect conflicts. (A transaction attempting a write generates a conflict when updates invisible to it appear on the update chain. This causes the write operation to return WT_ROLLBACK. Visibility is computed by first using the transaction ID to detect uncommitted changes, and then by checking the read timestamp of the updater against the update's commit timestamp.)
At reconciliation time the visibility code picks the update that should appear on the disk page (generally, the latest committed value; see History Store) and converts it to a time window. The value's commit time provides the start portion of the time window; if the value is followed by a tombstone, the tombstone provides the stop time, and if it is not, the stop time is set to "none". This time window is then packed into the on-disk value cell along with the value.
When a read needs to examine the on-disk value rather than an update, the unpack logic unpacks the time window as well as the value and proceeds accordingly. Ordinary unpacking (though not the "careful" unpacking used by verify) checks for obsolete transaction IDs that should not be seen (based on write generation) and clears them. This process does not clear old timestamps, however. Old timestamps are cleared explicitly during reconciliation before cell packing.
Prepared transactions get two additional timestamps: the prepare timestamp and the durable timestamp. The prepare timestamp is the point at which the transaction is prepared, which can be less than the commit timestamp, and the durable timestamp is the time at which the transaction becomes stable, which can be greater than the commit timestamp. These times are permitted to diverge is so that distributed two-phase commit can reach consensus, which can be slow, without holding up advancement of the stable timestamp. The prepare timestamp must be greater than the stable timestamp as of when the prepare begins, and the durable timestamp must be greater than the stable timestamp as of when the transaction commits.
Reads between the prepare timestamp and commit timestamp of a transaction that has been prepared but not committed fail with WT_PREPARE_CONFLICT.
Reads between the commit timestamp and durable timestamp of a transaction that has been committed but is not yet stable (that is, the stable timestamp is at or past the commit timestamp but has not yet advanced to the durable timestamp) are potentially unsafe. If a second transaction performs such a read and then commits with an earlier durable timestamp, and a checkpoint includes the second transaction's stable timestamp but not the first, that checkpoint then contains inconsistent data. Avoiding this inconsistency is, for the time being at least, the application's responsibility.
See Prepared Transactions for further discussion of prepared transactions.