 |
Version 12.0.0
|
|
Version 12.0.0
|
A tiered table is a single btree (possibly with multiple checkpoints) made up of blocks that reside in one or more files on the local file system and zero or more cloud objects (e.g., stored in S3). The btree spans this set of files and objects by encoding a block's location in the pointer that links blocks in the btree. A tiered btree is contrasted with a regular (non-tiered) btree that is contained in a single file.
When in use, a tiered btree, like a regular btree, may have some recently used or modified data that resides in memory pages. This in-memory representation is the same between a tiered btree and a regular btree, it is only how data is stored on disk and in cloud objects that makes these btrees different.
All writes (i.e., pages that are reconciled and written to storage by eviction or checkpoint) are written to a designated file, called the active file. All other files and objects that are part of the tiered table are read-only. Each object or file is given an object number, which appears as part of its name on disk, in cloud storage and in metadata.
When a tiered btree is created, there is a single file associated with it, it is given object number 1. This is the active file, and it only resides on disk. This is always true for an active file. When a file ceases to be an active file, writes to it will no longer be permitted. At that point, such a file can be copied to cloud storage. How this transition to a new active file occurs is the subject of the next section.
A fundamental operation for a tiered table is flush_tier, this occurs as a result of a call to WT_SESSION::checkpoint with a configuration string that includes "flush_tier=(enabled=true)". Because flush_tier is a part of checkpoint, it is a system-wide operation. Thus, flush_tier allows the data for all tiered btrees to move from the local file system to object storage.
A flush_tier checkpoint has a slightly different sequence of operations from a regular checkpoint without flush_tier. For each tiered table, a new active file is created, data is checkpointed to the old active file (see Checkpoints), and when that is completed, the old active file is copied to object storage in the background.
As each object storage write completes, the local file that was the source of that write will be removed. The removal is coordinated with any active readers of that file. Since the file is no longer an active file, by definition there can be no outstanding writers to the file, only readers.
A user of the WiredTiger API does not need to be aware of this coordination. Cursors may remain open on a tiered table, and reads, writes and transactions may occur as usual, unaffected by the machinery of the flush_tier. Generally the changes to an application are minor:
"flush_tier=(enable=true)" on calls to WT_SESSION::checkpoint. flush_tier need not be specified on every checkpoint call; typically the cadence of flush_tier is much less than the cadence of ordinary checkpoints.At the moment, the internal checkpoint server, that is started via the checkpoint configuration option to wiredtiger_open, does not have the ability to enable flush_tier. That means that applications that rely on the internal checkpoint server must add their own checkpoint calls, usually in a separate thread, in order to accomplish a flush_tier checkpoint.
The figure below provides a high level overview of flush_tier, showing the state of a single tiered table over time. The green arrows at the top of the figure indicate write requests. These come from eviction, except during checkpoint processing. At T0, we start with two objects in object storage, Object 1, and Object 2, and File 3 as the writable active file. At T1, we start a flush checkpoint. At T2, that checkpoint completes, and WiredTiger switches the writable active file from File 3 to File 4. At this point there should be no outstanding writes to File 3 because the checkpoint has completed and eviction to the table is disabled. All future writes will go to File 4. So we can queue the copy of File 3 to object storage. The copy completes at T3. At any later time (T4) WiredTiger can remove File 3 from the local file system.
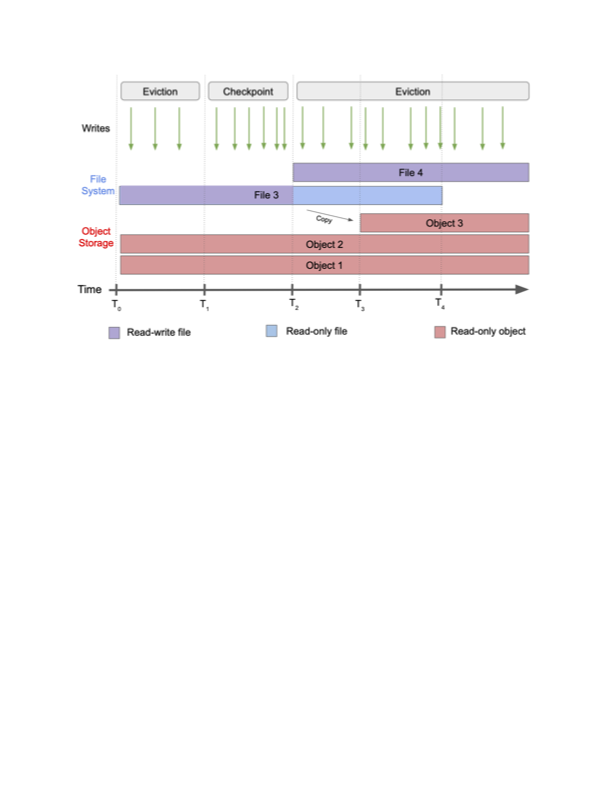
Figure 1: Flush tier operation.