 |
Version 12.0.0
|
|
Version 12.0.0
|
 | Data Structures | Source Location |
|---|---|---|
| |
Caution: the Architecture Guide is not updated in lockstep with the code base and is not necessarily correct or complete for any specific release.
Cursors are used in WiredTiger to get and modify data. A caller of WiredTiger uses WT_SESSION::open_cursor to create a WT_CURSOR. Methods on the WT_CURSOR can then be used to position, iterate, get, and set data. In the typical case, a cursor will be used to access keys and values in a Btree. However, cursors can also used to access indexed data, WiredTiger statistics, log files, and metadata. Additionally, cursors are used for managing backups.
The various kinds of cursors are created by the WT_SESSION::open_cursor call. Depending on the uri used when opening a cursor, the cursor will be implemented internally as one of the many cursor structures that include WT_CURSOR_BTREE, WT_CURSOR_BACKUP, WT_CURSOR_INDEX, WT_CURSOR_LOG, WT_CURSOR_METADATA, WT_CURSOR_STAT, WT_CURSOR_TABLE. Each of these structures starts with the common WT_CURSOR structure, which contain all of the data and method pointers that make up the public part of the API. Thus, any one of these "extended cursor structs" can be allocated and returned as a WT_CURSOR pointer. Since the method pointers are filled with a specific implementations, for example __curtable_reset, a call to WT_CURSOR::reset will call the specific implementation function, and the first argument can be cast to be a pointer to the cursor struct used by the implementation. Thus, in our C code, we have something similar to a class hierarchy, having an abstract base class (WT_CURSOR) with virtual methods, and a number of implementation classes.
The code for each cursor type's methods are generally organized in a single file. For example, a backup cursor is implemented in src/cursor/cur_backup.c . Similarly, shared or utility cursor methods are defined in src/cursor/cur_std.c .
Several cursor types have the concept of subordinate cursors, or child cursors. For example, a table cursor is composed of subordinate file cursors, each representing a column group. A metadata cursor has a subordinate cursor that is a file cursor on the metadata file.
Every open cursor appears on a list in WT_SESSION->cursors. This list is ordered in a way that cursors are closed when the session is closed. Thus, if a subordinate cursor needs to be closed before its parent, it must be listed before the parent.
Cursors that expose Btree data, like file, table and index cursors, return a set of keys and values, translating encoded data to types that match the schema. For example, if the value_format specified for a table is "iSi" (an integer, a null-terminated string, an integer), then data {0, "abc", 5} might be stored in the Btree in a packed format as:
When retrieved, the values are decoded and stored into typed variables whose addresses are passed to WT_CURSOR::get_value.
As an aside, 0x80 represents 0 using a variable length encoding. Using 0x80 as zero allows negative integers to be stored (-1 is 0x7f) in a way that they will sort before zero and positive integers. Small integer values can be stored in a single byte. See comments in src/include/intpack_inline.h for more information.
When creating a cursor via WT_SESSION::open_cursor, the raw flag can be used. This has the effect of disabling the translation provided by the schema, transferring a single block of unencoded data for the key or value.
File cursors (also known as Btree cursors) are one of fundamental kind of cursors, allowing direct accesses to WiredTiger Btrees. The implementation structure for a file cursor is WT_CURSOR_BTREE. The file cursor methods are generally small wrappers around calls into the Btree layer, where the WT_CURSOR_BTREE structure is used. The Btree layer handles all aspects of cursor positioning, and transfers of raw key and value data.
A table cursor is a higher level concept built on file cursors. A WiredTiger table allows data to be physically split into separate Btrees, this is done via the concept of column groups. Column groups may be defined that contain a set of named columns (columns are synonymous with fields). Each column group's columns are the stored in a single btree and may be looked up by the table's key. See Column groups for API details.
Tables may also have indices. These are implemented as Btrees mapping the index key(s) to the main key(s) of the table. Indices may be added after the data is populated in the main table. This requires the index to be filled at the time it is added. Index cursors are implemented using WT_CURSOR_INDEX. Methods on this cursor that set and get values know to use the value that appears in the index as a key into the main table. See Indices for API details.
Internally, we define the concept of a "simple" table as one that has no named columns. Columns, that is the set of keys and values, may be optionally named when creating a table. With no named columns, column groups are not possible (as they must reference names), and all of a table's keys and values reside in a single file. Also without named columns, there is no possibility that a cursor can use projections. A "simple" table, by its nature, can be implemented by a single Btree file and needs no special translation. Thus, if a cursor is opened on a "simple" table, we can return a file cursor on the single file used to store its data, instead of a table cursor. This optimization means that every cursor method goes directly to the file cursor implementation, saving CPU time throughout the lifetime of the cursor.
Projections are an indication, when a cursor is opened, that the indicated values, and possibly some keys, should be returned by WT_CURSOR::get_value calls. This is only available for table cursors. If the table was configured with column groups, a projection has a bearing on which column group files must be opened in a cursor. When a subset of values is returned, it's possible that some column groups will not be needed. To implement projections and column groups, cursors use a plan.
A plan is a string that indicates a series of actions that must be taken to retrieve the needed values from the subordinate cursors in the table cursor. Remember that each column group gets its own cursor. When a table is created, a default plan is created that asks to copy all columns from each column group cursor in order. When a projection is used for a cursor, a more complex plan may be created. A plan contains numbers and action letters. The numbers are arguments, the action letters are commands. The actions 'k' and 'v' indicate that the subordinate cursor indicated by the numeric argument will be used to get keys or values that follow. The 'n' action gets one or more next key or value columns from the cursor. The 's' skips one or more columns. Switching to another cursor resets the cursor to point at the first column in the indicated cursor. This allows a way to find keys and values in arbitrary order.
As a contrived example, suppose we have a table with two keys "k1,k2" and four values "x1,x2,x3,x4". The column groups are created as follows:
The column group "main:c1" has keys "k1,k2" and values "x1,x2"; the column group "main:c2" has keys "k1,k2" and values "x3,x4". A table cursor on the main table will have two sub-cursors, one for each column group. Now consider the ill-considered projection that is opened as:
In this case, the plan is this string (with spacing added):
To break it down,
"0v" means use sub-cursor 0 and prepare to read values."n" means get the next value, that is "x1"."1v" means use sub-cursor 1 and prepare to read values."s" means skip a value, that is "x3"."n" means get the next value, that is "x4".Notice that this plan requires many switches of cursors and several "s" (skip) operations. Each skip involves enough decoding of the data item to determine its length so its data can be skipped over.
With the default (complete) projection, getting values is fast. Using the default plan, the needed columns are pulled out of each subordinate cursor one by one, and get copied to the caller's arguments. With projections, the simple algorithm following the plan works well if the columns in the projection are grouped by column group and requested in order. Without that discipline, as in this example, the performance will not be optimal.
The implementation of plan creation and execution resides in the Schema.
Dump cursors are used in two rather different ways. Regular dump cursors retrieve the raw keys and values and translate bytes either as raw characters or as hex values. This flavor of dump cursor is used by the wt dump or wt dump -x utility. JSON dump cursors do more sophisticated translation, returning a string that is a JSON formatted record, with the name for each key and its data and the name for each value and its corresponding data. Data is translated to either integral, floating point, or string depending on the format of the column in the schema. This flavor of dump cursor is used by the wt dump -j command as part of creating a JSON dump of a WiredTiger table or file.
There is a single WT_CURSOR_DUMP struct that is used to implement both flavors. The dump code checks for the WT_CURSTD_DUMP_JSON flag and as needed, calls into functions in src/cursor/cur_json.c . The code in that file also implements several external functions that are used by the wt utility when loading JSON-dumped files. In particular, the __wt_json_token function returns individual JSON tokens from an input string.
The JSON code used by the dump cursor uses some storage that hangs off of cursor->json_private which is typed as WT_CURSOR_JSON. When a JSON flavored cursor is created, the list of key column names and value column names is populated in WT_CURSOR_JSON. These names, obtained from the configuration string that created the table or file, are useful to have in advance, as they are used once per row to help fill out the JSON output. The functions that get rows iterate these names and unpack the corresponding column data, converting them into the appropriate JSON format for the data.
A backup cursor is used to manage backups. It is implemented using a WT_CURSOR_BACKUP structure. A backup cursor can be configured to do a full backup or an incremental backup. First, we'll look at full backups.
A backup cursor for a full backup returns the set of files that need to be copied to achieve the backup. The backup cursor, when opened, ensures that it is the only backup cursor running in the system and returns an error if not. This is managed using the WT_CONNECTION_IMPL->backup.start variable, which is guarded by the hot backup read-write lock backup.lock. A non-zero value means a hot backup is in progress. Closing the backup cursor sets it back to zero.
Having an open backup influences actions elsewhere in WiredTiger, since part of the backup protocol involves the application copying whole data files. Thus, having an open backup may cause the block manager and log file server thread to avoid truncating data and log files. A truncation of a file being copied by the application would be unexpected. Also, open checkpoints are not deleted during the course of a backup.
When the backup cursor is initialized, the complete set of files needed to back up is generated and stored in the cursor. This makes the backup's next function easy as it just returns the next file in the list.
Incremental backups work much the same way, except that the file list is reduced to files that have changed since a previous backup referenced in the configuration when the cursor is opened. The other twist is that for each file returned, the caller does a duplicate operation on the backup cursor, and the duplicate code actually returns a specialized incremental backup cursor. This kind of cursor has its own next method that causes it to return information about individual pieces of this file that need to be copied. The code to implement incremental cursors is in src/cursor/cur_backup_incr.c .
Cursors may be duplicated, this occurs by passing a cursor to be duplicated as part of the WT_SESSION::open_cursor call. Cursor duplication does not occur in the cursor type code. Rather, a new cursor of the requested type is created, and the cursor's position is duplicated via a call to __wt_cursor_dup_position. This function gets the key from the original cursor in raw form (not converting it using key_format), sets the key in the new cursor, and does a search to set the position properly.
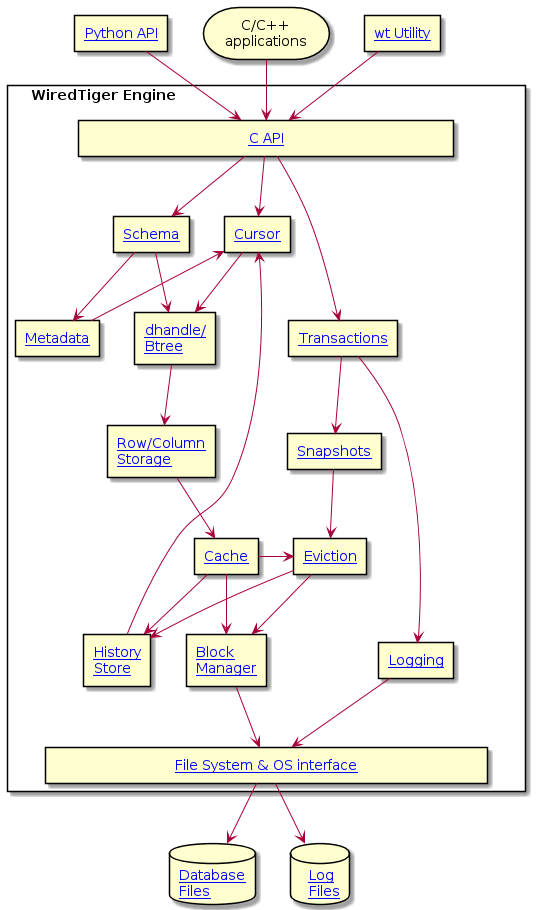
File cursors, Btrees and data handles exist in a WiredTiger system as different ways to reference the data in a Btree. It is useful to understand the differences between these structures and how they are used.
At the bottom is the data handle (also known as dhandle). This is an abstraction of an operating system file handle, with a set of flags and some reference counts. A Btree is a much larger abstraction, with a memory cache of key value pairs along with functions to read and write data as needed to and from the data file. A Btree is paired with a data handle to allow the transfer of data. Both the data handle and the Btree are owned by the connection. That is, they are shared among all sessions.
File cursors, on the other hand, are owned by a session. When a session opens a cursor on a file for the first time in that session, a file cursor is created. This occurs even if the file may be opened by cursors in other sessions already. The session owns the cursor, and the cursor may only be used by that session. Open cursors do increment reference counts in the data handle, so that the data handle "knows" it is being used, so that the file may not be dropped, renamed, verified or salvaged. So when WT_CURSOR::close is called for a file cursor, the cursor's memory may be released (or retained if cached), and reference counts decremented. Other sessions may retain open cursors on that file, they are independent.
Cursors, upon closing, may be cached in the session. An open of the same URI will return a cached cursor if one is found matching the URI. Cursor caching is currently only done on file cursors. Because of the optimization for simple tables described above, cursors on simple tables are also cached.
To help implement caching, two methods, cache and reopen have been added to the cursor API. These are not public. Their function is to perform cursor-type specific operations to change a cursor from an open state to a cached state (cache) and change from a cached state to the open state (reopen).
When a cursor is opened the first time, it is marked as cacheable or not. Cursors that specify certain options, like bulk loading, random, or readonly, are not cacheable. When a cursor is closed, the cursor is checked if it is cacheable. If so and if cursor caching is enabled in the session, then it will be cached. Cached cursors live in a hash table that is owned by the session. A hash function on the URI is used to determine which hash bucket to use. We compute the hash of the URI once, its value is stored in in the cursor for future use. Thus, caching a cursor (what happens within the type-specific cache function, e.g. __curfile_cache) is relatively quick:
dhandle->references).dhandle->session_inuse).The change of reference from a strong to a weak is significant. When a dhandle's session_inuse (strong reference) drops to zero, it means that no cursor is open on the dhandle, and the only references are from cached cursors. In this state, the dhandle may be marked dead by the dhandle sweep. When the dhandle is dead, the dhandle's memory will still persist, but each session will eventually notice, during its cursor cache sweep, and "fully close" the cursor, removing it from the cache list, releasing its weak reference before freeing the cursor. Each session holding cached cursors must have some periodic activity that causes it to run its sweep, an occasional call to WT_SESSION::reset will suffice. After a dhandle has been dead for enough time, it is expected that all of its weak references will drop to zero, and the dhandle itself can be freed by the dhandle sweep.
If there is a failure during the cache function, then we would want to fully close the cursor. Rather than having special case code to handle this rare condition, we instead call reopen to temporarily bring the cursor back to an open state, and turn cursor caching off temporarily in the session while we close the cursor, releasing all its resources and references.
During a cursor open, if the cursor configuration options allow caching, we hash the uri, and look at the corresponding hash bucket in the session cursor cache. If we find a matching cursor, we call reopen on the cursor. This is what happens within the call to the type-specific reopen function (e.g. __curfile_reopen):
dhandle->session_inuse).dhandle->references).If the reopen fails (probably due to the dhandle no longer being open or being marked dead), we have ensured that enough of the cursor is opened so that it can be legally closed. We have studiously avoided having a cursor that is in some state that is half-open and half-closed, as it is hard to know how to dispose of it.
Consider a large system that has many sessions using the same set of tables. When all sessions have closed a particular table, there will be no need to keep the underlying data handle open. In fact, if a WT_SESSION::drop call is called, we want to ensure that the data handle has been closed and the corresponding file is removed. Some systems, like Windows, require that all open file handles be closed before a file can be successfully removed from the file system. So there is motivation to periodically mark data handles that have no active references, and have sessions free cached cursors that have weak references to such marked data handles. The former job occurs in the connection sweep code. The latter job occurs in the session cursor cache sweep.
The session cursor cache sweep currently happens in the WT_CURSOR::close call, and also on calls to WT_SESSION::reset. On one hand, we don't want the overhead of a sweep to occur too frequently. It is quite possible that both close and reset can be called a lot and there may be many of thousands of cached cursors in the session. For that reason, we'd like to do the sweep in small increments, and not on each call. On the other hand, in a larger system, a session may be part of a pool servicing higher level requests. When a session completes its work, it may be left idle by the caller of WiredTiger, and such a session may then be idle for long periods of time. When cursor caching is enabled and sessions are not active, we want even occasional calls to WT_SESSION::reset to have a strong effect. We want occasional sweeps to keep up with freeing up references to data handles, so that otherwise unused data handles may in turn be freed eventually.
Our solution to this is three-fold. First, every time we want to call the sweep, a countdown counter is used, so we only consider a sweep every WT_SESSION_CURSOR_SWEEP_COUNTDOWN times (currently WT_SESSION_CURSOR_SWEEP_COUNTDOWN == 40). Secondly, we won't sweep if it's already been done this second in time. Finally, we sweep by walking a small set of buckets, initially 5 out of typically 512 configured buckets. However, depending on how productive our sweep is, that is, how many references to closed data handles are freed, we may continue our walk. This should usually strike a good balance between not having a lot of overhead for sweeps, and keeping up with the need to free up shared resources.
Range bounded cursors provide a mechanism for optimizing cursor operations in collections with a large number of invisible records. When traversing records the record's key is compared with the bounds set on the cursor and the traversal will exit with WT_NOTFOUND regardless of whether the value associated with the cursor is visible.
The lower and upper bound in a cursor is represented as a WT_ITEM. The implementation applies bounds through the function __wt_cursor_bound which takes the cursor and a config string as arguments. The config string specifies whether the operation is clearing or setting the bound, and if a "set" is in progress, whether the bound is a lower or upper bound. There are four flags that can be set when applying bounds: WT_CURSTD_BOUND_LOWER, WT_CURSTD_BOUND_LOWER_INCLUSIVE, WT_CURSTD_BOUND_UPPER, and WT_CURSTD_BOUND_UPPER_INCLUSIVE. When calling __wt_cursor_bound with valid bounds, the respective bound flag is set and the key held on the cursor is copied into the relevant bound buffer. When a bounds is set, a copy of the bounds key is made and is kept by the cursor. Thus the memory used for the key when making the cursor->bound call does not need to be retained by the application. Clearing a cursor's bounds can be done via resetting the cursor or calling bound with the "clear" config which will free both bounds buffers.
When calling cursor->next and cursor->prev on an unpositioned cursor, WiredTiger guarantees that the cursor will start walking from either the start or end of the file respectively. The range bounded cursor logic continues to uphold this guarantee. Doing so requires additional logic to place the cursor at the start or end of the range. In cursor->next and cursor->prev, the cursor gets positioned with the function __wt_btcur_bounds_position. This attempts to position the cursor on the appropriate bound for the direction of traversal (e.g. lower bound for next). If the bound exists, the cursor will be positioned on the bound, if not it could be positioned on the closest valid record (meaning within the bounded range), or the record just outside of the range. In the case it's positioned just outside the range, this is still acceptable as it will be marked as "needing walk", and the following traversal (whether next or prev) will continue, returning a record within range at completion.
In cursor->search_near, __btcur_bounds_search_near_reposition is initially called. This function checks whether the given key to be searched for is within the bounded range. If not, the key to be searched for will be updated to be the nearest bound.
When cursors are positioned, their data may point to data in the btree or data allocated in the cursor. A caller may use a pointer to that data until the next cursor call. After that, the pointer should not be considered valid. By default, WiredTiger does not enforce this. When opening a cursor, a "debug=copy" configuration flag can be used. This forces any data that is returned by WT_CURSOR::get_key or WT_CURSOR::get_value to be in malloc'd memory, and explicitly freed on the next API call. Systems that are instrumented to track memory references can detect the references to freed memory, thus latent bugs can be detected.
The implementation is straightforward. The key and value in each cursor is represented as a WT_ITEM. A WT_ITEM includes a pointer and size, and it can point to arbitrary memory. However, the WT_ITEM also includes a memory buffer that may or may not be allocated. When the WT_ITEM pointer points to the item's own memory buffer, then it is already in malloc'd memory. When "debug=copy" is configured, it is a simple matter to check if a key and value being returned are already in the item's malloc'd memory. If not, memory is allocated, the copy is made and the item's pointer is updated. On the beginning of the next API call using that cursor, the item's malloc'd memory is overwritten and freed. Thus, in the presence of a memory tracker, uses of "stray" pointers will be detected. Even without a memory tracker, uses of "stray" pointers into the freed storage will likely yield the overwritten bytes, and not the previously seen key or value.
WiredTiger uses a pseudo-random algorithm for random cursors with the goal of deriving good random distributions while maintaining performance. Only the cursor->next function can be used to fetch a random record.
The algorithm starts from the root page being descended down randomly using WiredTiger's random number generator (RNG) until we reach a leaf page. Once we find a leaf page, we then evaluate three different conditions that determine our next steps to grab a record from the leaf page.
Failing all of the conditions, move to the previous or the next visible record in the btree a randomly decided number of times (between 0 - 250). Return the record that the cursor ends up stopping on. Note: The record can be fetched on a different leaf page than our original page that we descended down from.
The algorithm doesn't guarantee a complete randomness to the user and can lead to skewed results depending on the underlying tree structure. Examples of instances that could typically lead to these skewed results are:
The next_random_sample_size configuration is an option that can be used for users looking for a better distribution. The concept is that the btree becomes divided into next_random_sample_size pieces, and each subsequent cursor->next call will retrieve a random record from the following divided piece. Internally, this configuration results in a slight modification to the original pseudo-random algorithm described at the start of this section. The process remains the same except for Step 1, where instead of performing a random descent, the algorithm will now start from the beginning of the btree and traverse a fixed number of times to next the divided segment.