 |
Version 11.1.0
|
|
Version 11.1.0
|
 | Data Structures | Source Location |
|---|---|---|
| |
Caution: the Architecture Guide is not updated in lockstep with the code base and is not necessarily correct or complete for any specific release.
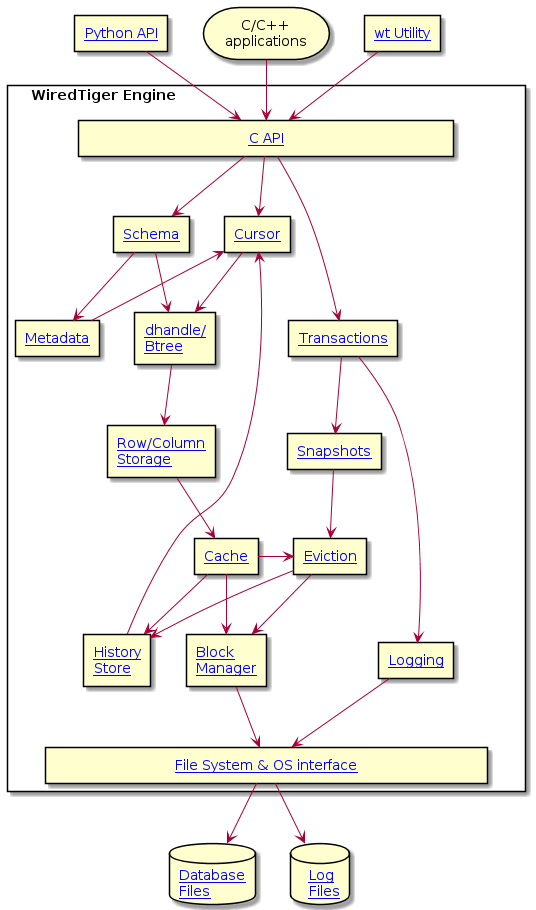
A schema defines the format of the application data and how it will be stored by WiredTiger. While many tables have simple key/value pairs for records, WiredTiger also supports more complex data patterns. See Schema, Columns, Column Groups, Indices and Projections for more information.
The format of keys and values is configured through key_format and value_format entries in Configuration Strings. WiredTiger supports simple or composite data formats for keys and values. See Format types for the full list of supported data types.
"key_format=i,value_format=S"."key_format=Si,value_format=ul". Cursors support encoding and decoding of these types of keys and values. See Data translation and Cursor formats for more details.Column store requires the key format to be defined as the record number 'r' type. Schema, Columns, Column Groups, Indices and Projections has more information on key/value formats.
Database schema defines how data files are organized in the database home folder:
"<table name>.wt", where "<table name>" is the name that was passed as a part of the name parameter to WT_SESSION::create."<table name>_<colgroup name>.wt". Where "<table name>" is the name that was specified as a part of the name parameter to WT_SESSION::create. And "<colgroup name>" is the column group name defined in the colgroups entry during the definition of the table format. See this example of how column groups can be configured in WiredTiger ex_col_store.c. Row Store and Column Store describes in more detail how row and column stores work."<table name>_<index name>.wti". Where "<table name>" is the table name passed into WT_SESSION::create. And "<index name>" is the index name defined during index creation. See Indices for more information on how to create a table index."<table name>-<chunk id>.lsm" files. Where "<table name>" is the name that was specified as a part of the name parameter to WT_SESSION::create. "<chunk id>" is the chunk index managed by WiredTiger. More information on LSM trees can be found on this page Log-Structured Merge Trees.A user can create and manipulate database objects through the API listed on this page Schema Manipulation. There are several WiredTiger internal objects such as Metadata, History Store, etc. The schema of those objects is locked and cannot be altered from outside of WiredTiger.
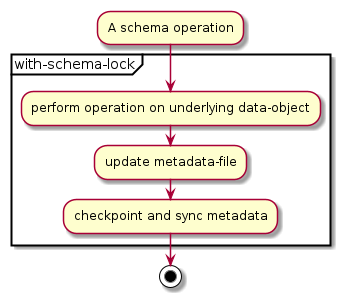
Schema operations cause an update to the metadata and are performed under the schema lock to avoid concurrent operations on the database schema. The following sequence of steps define a generic schema operation:
Apart from the schema API, the schema lock is necessary for many other operations in WiredTiger including the following "heavy" database modifications:
checkpoint prepare to avoid any tables being created or dropped during this phase. See Checkpoint for details.Rollback to stable operation acquires the schema lock to make sure no schema changes are done during this complex process. Rollback to Stable has more information on the operation.backup cursor also holds the schema lock because it must guarantee a consistent view of what files and tables exist while it is being used, so it prevents any tables or files being created or dropped during that time. See Backups and Backup cursors for more information.All the schema operations listed below perform multi-step metadata modifications. Although they are non-transactional, the schema code tracks the metadata changes and performs the file and metadata operations in a specific order to provide recovery in the case of a crash.
All schema manipulations are done in the context of WT_SESSION. All the methods below, except WT_SESSION::create and WT_SESSION::truncate, require exclusive access to the specified data source(s). If any cursors are open with the specified name(s) or a data source is otherwise in use, the call will fail and return EBUSY.
The create schema operation is responsible for creating the underlying data objects on the filesystem and then creating required entries in the metadata. The API for this operation is WT_SESSION::create.
WT_SESSION::drop operation drops the specified uri. The method will delete all related files and metadata entries. It is possible to keep the underlying files by specifying "remove_files=false" in the config string.
WT_SESSION::rename schema operation renames the underlying data objects on the filesystem and updates the metadata accordingly.
WT_SESSION::alter allows modification of some table settings after creation.
WT_SESSION::truncate truncates a file, table, cursor range, or backup cursor. If start and stop cursors are not specified all the data stored in the uri will be wiped out. When a range truncate is in progress, and another transaction inserts a key into that range, the behavior is not well defined. It is best to avoid this type of situations. See Truncate Operation for more details.