 |
Version 12.0.0
|
|
Version 12.0.0
|
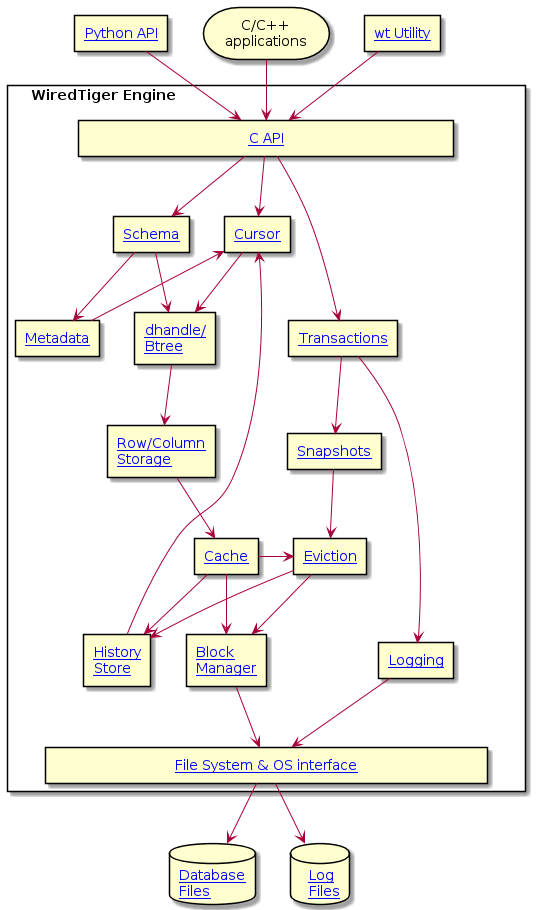 | Data Structures | Source Location |
|---|---|---|
| |
Caution: the Architecture Guide is not updated in lockstep with the code base and is not necessarily correct or complete for any specific release.
RTS is an operation that retains only the modifications that are considered stable. A modification is considered unstable if it has a durable timestamp greater than the stable timestamp or its transaction id is not committed according to the recovery checkpoint snapshot. The recovery checkpoint snapshot corresponds to the checkpoint transaction snapshot details saved at the end of every checkpoint.
RTS scans tables in the database to remove any unstable modifications. A table is selected by RTS if it meets one of the following conditions:
RTS might choose to skip a table for any of these reasons (this list is not exhaustive):
For each selected table, its pages are read into the cache. The unstable in-memory updates and the unstable historical versions from the history store are removed. The unstable on-disk version is replaced by the latest stable in-memory update if any, otherwise by the latest stable version from the history store. If there is no stable in-memory updates and no stable version in the history store, the data store entry is completely removed. In the situation where the table has no timestamped updates, all the historical versions related to this table are removed from the history store as they are no longer required and the on-disk value is preserved.
Finally, RTS is triggered on startup, shutdown or when the application is initiated. It is worth noting that RTS needs exclusive access to the database and no concurrent transaction is allowed.
For in-memory updates, RTS traverses all the updates defined in the update list and aborts every update until a stable is found. To remove any key from the table, RTS adds a globally visible tombstone to the key's update list and this key gets removed later during reconciliation.
For on-disk values, if the start time point is not stable and the update list does not contain any stable update, RTS searches the history store to find a stable update to replace the unstable on-disk version with. If the history store does not contain any stable update, the on-disk key is removed. If the stop time point exists and it is not stable, the on-disk update is restored into the update list.
RTS doesn't load pages that don't have unstable updates that need to be removed. This check is done by comparing the time aggregated values with the stable timestamp or the recovery checkpoint snapshot during the tree walk.
In the following scenario, there are 3 updates on the update list, an on-disk value, the history store is empty and the stable timestamp is 10:
Update list: U3 (30) -> U2 (20) -> U1 (10)
On-disk: U2 (20)
History store: U1 (10)
Stable timestamp: 10
RTS will mark all the unstable updates from the update list as aborted. The on-disk value will be replaced by the most recent stable update after reconciliation:
Update list: U3 (30) Aborted -> U2 (20) Aborted -> U1(10)
On-disk: U1 (10)
History store: Empty
Stable timestamp: 10
Let's consider a scenario where the history store is not empty:
Update list: U5(50) -> U4 (40)
On-disk: U3 (30)
History store: U2 (20) -> U1 (10)
Stable timestamp: 20
In this case, RTS will abort the unstable update from the update list again but will also move the latest stable update from the history store to the update list:
Update list: U2 (20) -> U5 (50) Aborted -> U4 (40) Aborted
On-disk: U2 (20)
History store: U1 (10)
Stable timestamp: 20
The last scenario covers the situation when the on-disk update is restored into the update list because the stop time point exists and it is not stable:
Update list: Empty
On-disk: U3 (30) with a stop timestamp (40)
History store: U2 (20) -> U1 (10)
Stable timestamp: 30
After RTS, we end up with the following state:
Update list: U3 (30)
On-disk: U3 (30)
History store: U2 (20) -> U1 (10)
Stable timestamp: 30
The main timestamps RTS are concerned with are the durable and stable timestamps. The high-level details are covered above, what follows is a more detailed view of how we use these timestamps.
In order to ensure that the system is in a quiescent state, in diagnostic builds we read the global pinned and stable timestamps at the start and end of RTS to assert they didn't change underneath us.
Once RTS has finished, we roll back the global durable timestamp to the stable timestamp, since if there are no unstable updates, the global durable timestamp can, by definition, be moved backwards to the stable timestamp.
Timestamps of updates in the history store can have some non-obvious properties:
The start timestamp can be equal to the stop timestamp if the original update's commit timestamp is in order. During rollback of a prepared transaction, a history store update with a stop timestamp may not get removed, leading to a duplicate record. RTS ignores the timestamps for these when checking ordering, and they're removed during the next reconciliation. When a checkpoint writes a committed prepared update, it's possible for further updates on that key to include history store changes before the transaction alters the history store update to have a proper stop timestamp. Thus, we can have an update in the history store with a maximum stop timestamp in the middle of other updates for the same key.
We also have some verification specifically related to the history store. While iterating over records, we check that the start time of a newly encountered record is greater than or equal to the previous record. We also validate that the timestamps in the key and the cell are the same (where possible).
Fast-truncate is worth mentioning briefly. If the page has a page delete structure, we can look at its durable timestamp, much the same as we would a normal page.
This is a little simpler than the timestamp rules - during recovery, we use normal snapshot visibility in most of the places we would look at timestamps (see the timestamps section).
We also clear the transaction ID of updates we look at during RTS, because the connection's write generation will be initialized after RTS and the updates in the cache would be problematic for other parts of the code if they had a "legitimate" transaction ID.
For example, suppose we restore an update from the history store with a transaction ID of 2000 and add it back to the update list. Later, after recovery, a new transaction starts with a minimum/maximum snapshot of (5, 10). This would not see the update because it's transaction ID (2000) is greater than the maximum snapshot of the new transaction. By removing the transaction ID, the update becomes globally visible, solving this problem.
We treat all data as visible when RTS is called from the API. Since we clear transaction IDs during RTS, we could also do this during the rollback that happens during startup and shutdown.
RTS touches the history store for a lot of things, primarily for deleting, but it might also need to read an update to move it to the data store.
The deletion code is called from the general update aborting code, where we might need to delete the first stable update we found when it came from the history store. There's also a somewhat subtle case where a new key can be added to a page, and then the page checkpointed, leading to a situation where we have updates to the key in the history store but not the disk image.
History store deletions are done using a standard history store cursor, starting at the highest possible start timestamp, and removing keys from newest to oldest until we hit an update with a start timestamp less than or equal to the rollback timestamp.
Note: in-memory databases don't have a history store, so none of this section will apply.
This is one of the simplest parts of the RTS subsystem, as a metadata cursor is specifically designed for these sorts of "iterate over a B-Tree" operations. We use this functionality for RTS, with the caveat that we tweak a few options so that corrupt or missing files don't raise errors. The reasoning here is that RTS is orthogonal to salvage, and might be called as part of salvage, so we simply need to "do our best". We do log the issues we find, however.
Less obviously, the history store needs one final inspection regardless of whether any other B-Trees were touched. This is because we usually rely on getting to the history store "via" the data store, but if we don't touch a B-Tree, that doesn't mean there aren't updates in the history store after the stable timestamp.
RTS tries to avoid looking at a page if it can. There are two ways we can avoid instantiating a page: if it was truncated at/before the stable timestamp, or if the page state is on-disk. If neither of these are satisfied, we need to instantiate the page to look at it, but that doesn't mean we look at the contents. Rather, we use the existing tree walk custom skipping functionality to check the page metadata, stuff like reconciliation results. These checks are fairly low-level, so they're outside the scope of this document.
One final note is that we deliberately do not call RTS for internal pages, as they do not have updates. They are still read into the cache in order to navigate to their leaf pages.
While the details of what happens here depends on the page type (row-store or VLCS), the overall idea is the same: we start by looking at the insert list (i.e. any items inserted before the first key on the page), iterate over all of the keys on the page, then look at the append list (i.e. any items inserted after the last key on the page). We mark the page as dirty so that we reconcile it in future.
The mechanics of deleting items (or inserting tombstones) from these places are quite involved, and out of scope for the architecture guide.
Checkpoints cannot be performed while RTS is running, even if they start before RTS. This is part of the contract that the system must be in a quiescent state before running RTS, but it's also enforced by taking the connection's checkpoint lock.
Upon completion of RTS, a checkpoint is performed so that both in-memory and on-disk versions of data are the same. It's possible for users to opt out of this, for example if they intended to do a checkpoint shortly after RTS anyway.
Eviction doesn't directly interact with RTS in any special way, but it's worth pointing out that RTS is likely to generate a large number of both clean and dirty pages, causing some amount of extra cache pressure. The clean pages can be evicted trivially, but the dirty pages will need to be written out, causing a potentially large amount of I/O. Eviction triggers and targets apply the same way during RTS as they do at any other time.
Dry-run mode is a way of running RTS without making any changes to on-disk or in-memory data structures, including the history store. It uses the same code as normal RTS wherever possible, making it ideal for checking what RTS would do on a given system, without disturbing it. One limitation is that it still needs to take the same locks as real RTS, so the system must still be quiescent.
Dry-run mode does not, however, increment all of the same statistics as normal RTS. As a rule, it only updates statistics that reflect what it's doing. For example, it will increment statistics about the number of trees and pages visited, but it will not change any statistics about the number of updates aborted (since it is doing real work visiting pages, but it isn't aborting any unstable updates).
Dry-run mode will cause similar cache pressure to the normal RTS, since it must visit the same trees and pages. There is a slight difference around eviction though, since it will not mark any pages as dirty, meaning eviction should have a much easier time cleaning up after a dry run.
There is an internal form of rollback to stable which can operate on a single object, called rollback_to_stable_one. The API requires a URI is passed in, which contrasts to rollback_to_stable where it will deliberately look at every single tree in the database.
This is primarily used for salvage. Salvage accepts a single URI to attempt fixing, so we don't want normal RTS to potentially read everything, especially when the database is in a state where salvage needed to be called in the first place.