 |
Version 12.0.0
|
|
Version 12.0.0
|
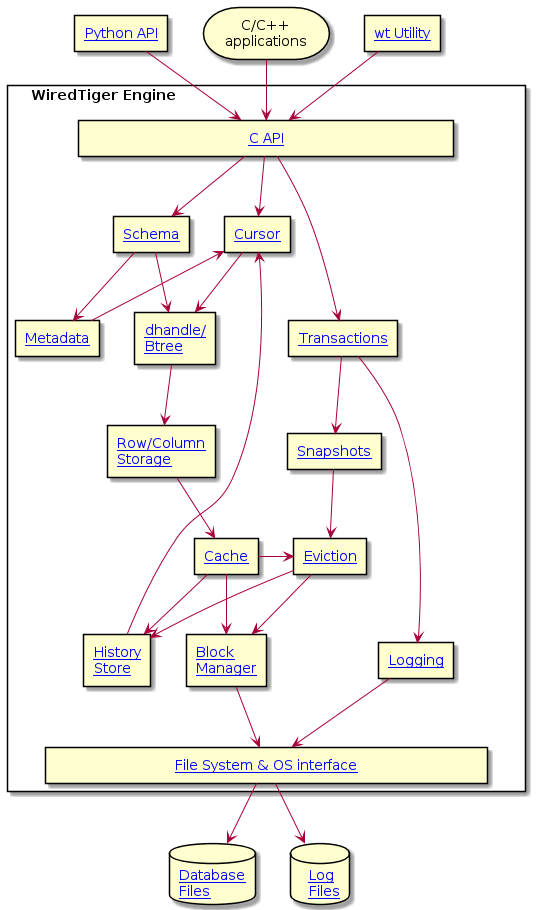 | Data Structures | Source Location |
|---|---|---|
| |
Caution: the Architecture Guide is not updated in lockstep with the code base and is not necessarily correct or complete for any specific release.
Backup in WiredTiger can be performed using the "backup:" cursor. WiredTiger supports three types of backups.
The following page describes how backup works inside WiredTiger. Please refer to Backups for details on how to use each of these types of backups.
When the application opens a backup cursor, internally WiredTiger generates a list of all files in the database that are necessary for the backup and creates a file which contains the snapshot of the metadata called WiredTiger.backup. WiredTiger takes both the checkpoint and schema locks to block database file modifications to generate a list of files required for backup and those locks are released once the list is generated. There is a contract that all files that exist at the time the backup starts exist for the entire time the backup cursor is open. This contract applies to all files in the database, not just files that are included in the generated list. The WiredTiger.backup file is also included in the backup list and is used upon the restore of a backup, to create the WiredTiger.wt metadata file. After WiredTiger.wt is created the WiredTiger.backup file is removed. Note that we do not use WiredTiger.wt as the metadata source and it is not included in the backup list, because the metadata can be modified after the list has been generated.
WiredTiger log files are also part of the generated file list for backup. There is a contract that the log files do not contain or make visible operations that are added to the log after the backup started that could have adverse affects during recovery and restore. Therefore WiredTiger forces a log file switch when opening the backup cursor. To fulfill the earlier contract that all files must exist during backup, WiredTiger does not use any pre-allocated log files nor does it remove log files during the time the backup cursor is open.
Once the backup cursor is opened successfully, any checkpoints that exist on the database before backup starts must be retained until the backup cursor is closed. All the newer checkpoints that are created during the backup in progress are cleaned whenever a newer checkpoint is created.
Block-based incremental backup is performed by tracking the modified blocks in the checkpoint. Whenever a new checkpoint occurs on a file, any new or modified blocks in this checkpoint are recorded as a bit string. This bit string information is updated with every new checkpoint.
Whenever an incremental backup cursor is opened to perform a backup, WiredTiger returns all the file offsets and sizes that are modified from the previous source backup identifier. WiredTiger returns the full file information to be copied for all the new files that are created, renamed or imported into the database after the incremental backup cursor is opened. Refer to Block-based Incremental backup for more information on how to use block-based incremental backup.
When a backup cursor is opened with the target configuration string as "target=", WiredTiger internally generates a list of targeted files instead of all files like a full backup. If the targeted object is a table, all the indexes and column groups of the table are also backed up.
Note: There can only be one backup cursor open at a time unless using duplicate backup cursors. Duplicate backup cursors are used for catching up with log files or with block-based incremental backup. Please refer to Duplicate backup cursors for more details.