 |
Version 11.0.0
|
|
Version 11.0.0
|
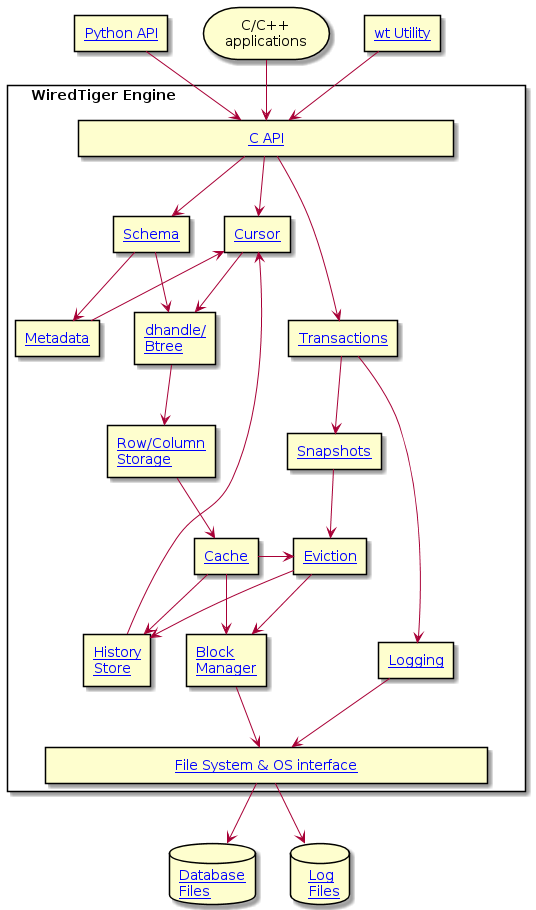 | Data Structures | Source Location |
|---|---|---|
| |
Caution: the Architecture Guide is not updated in lockstep with the code base and is not necessarily correct or complete for any specific release.
WiredTiger stores databases in a durable format through writing data to files it has created in the database directory. These include data files representing tables in a MongoDB database, a history store file used to track previous versions of the database tables, as well as other metadata files for the entire system.
Data files are denoted by the .wt suffix. The history store file (WiredTigerHS.wt) and the metadata file (WiredTiger.wt) are special WiredTiger files, but have the same underlying structure as normal data files.
In memory, a database table is represented by a B-Tree data structure, which is made up of nodes that are page structures. The root and internal pages will only store keys and references to other pages, while leaf pages store keys, values and sometimes references to overflow pages. When these pages are written onto the disk, they are written out as units of data called blocks. On the disk, a WiredTiger data file is just a collection of blocks which logically represent the pages of the B-Tree.
The layout of a .wt file consists of a file description WT_BLOCK_DESC which always occupies the first block, followed by a set of on-disk pages. The file description contains metadata about the file such as the WiredTiger major and minor version, a magic number, and a checksum of the block contents. This information is used to verify that the file is a legitimate WiredTiger data file with a compatible WiredTiger version, and that its contents are not corrupted.
Pages consist of a header (WT_PAGE_HEADER and WT_BLOCK_HEADER) followed by a variable number of cells, which encode keys, values or addresses (see cell.h). The page header WT_PAGE_HEADER consists of information such as the column-store record number, write generation (required for ordering pages in time), in-memory size, cell count (the number of cells on the page), data length (the overflow record length), and the page type. This is immediately followed by the block header WT_BLOCK_HEADER which contains block-manager specific information such as flags and version.
After the page header, pages with variable-length keys or values will have a set of cells. There are four main types of cells - keys, data, deleted cells, and off-page references. Cells are also usually followed by some additional data depending on its type. For example, values may have a time validity window, and off-page references may have a validity window and an address cookie. Ordering is important, values are all associated with the key that precedes them. Multiple values may be present, which can represent multiple versions. Extremely large values may be represented as a reference to another page (see overflow pages).
Fixed-length column store pages contain a block of bitmap data after the page header; after this there may be an auxiliary header followed by zero or more cells that are used to hold any auxiliary data (currently, time validity windows) associated with the values in the bitmap.
The exact encoding of cells is rather complex, and beyond what can be described here. The encoding strikes a balance between data that can be compacted efficiently in time and space, extensibility, and compatibility with previous versions.
Different types of pages are made up of different types of cells.
(1) Internal Pages - as the B-Tree grows in size and layer/s are added, there will be pages between the root page and leaf page. These internal pages contain keys that point to other pages.
WT_PAGE_ROW_INT is made up of a key cell (WT_CELL_KEY or WT_CELL_KEY_OVFL) followed by an off-page reference (WT_CELL_ADDR_XXX).WT_PAGE_COL_INT simply contains an off-page reference.(2) Leaf Pages - leaf pages consist of a page header, followed by keys, values or addresses (these reference overflow pages).
WT_PAGE_ROW_LEAF is made up of a key cell (WT_CELL_KEY or WT_CELL_KEY_OVFL) followed by a value (WT_CELL_VALUE/VALUE_COPY/VALUE_OVFL).WT_PAGE_COL_VAR is made up of data cells (WT_CELL_VALUE/VALUE_COPY/VALUE_OVFL) or deleted cells (WT_CELL_DEL). The page header has a starting record number, so the associated keys for all column store values is deduced by their position in the page.WT_PAGE_COL_FIX is made up of, first, a block of bitmap data, and then an auxiliary header followed by key cells (WT_CELL_KEY) alternating with value cells (WT_CELL_VALUE). The keys hold record number offsets from the page start; the value cells are always empty values, but include validity window information for values in the bitmap data. Cells for items with no validity window information are not written. Pages needing no validity window information at all do not contain the auxiliary header either.(3) Overflow Pages - overflow pages are needed when keys/values that are too large must be stored separately in the file, apart from where the item is logically placed. Page sizes and configuration values such as leaf_key_max and leaf_value_max are used to determine overflow items.
While the above gives a general overview of how different page types are structured, it is a simplified representation. Due to the large amount of data being stored, WiredTiger may compress data to preserve memory and disk space. Keys may not be stored in their entirety when prefix compression is used (the identical key prefix is stored only once per page to reduce size). In addition, each block written may be compressed and/or encrypted. The header portion of each block remains uncompressed and unencrypted.
When data needs to be read from a data file, it is unpacked into in-memory structures, and vice versa, we pack the contents when we want to write a page image to a data file. Low level functions that pack or unpack the contents of individual cells are in cell_inline.h. Functions like __wt_cell_unpack_kv and __wt_cell_unpack_addr to unpack keys, values and addresses are found here, and uses of such functions appear in the B-Tree code. Similarly, there are __wt_cell_pack_* functions to pack particular kinds of keys, values and addresses; these are used in the reconciliation code.