 |
Version 10.0.2
|
|
Version 10.0.2
|
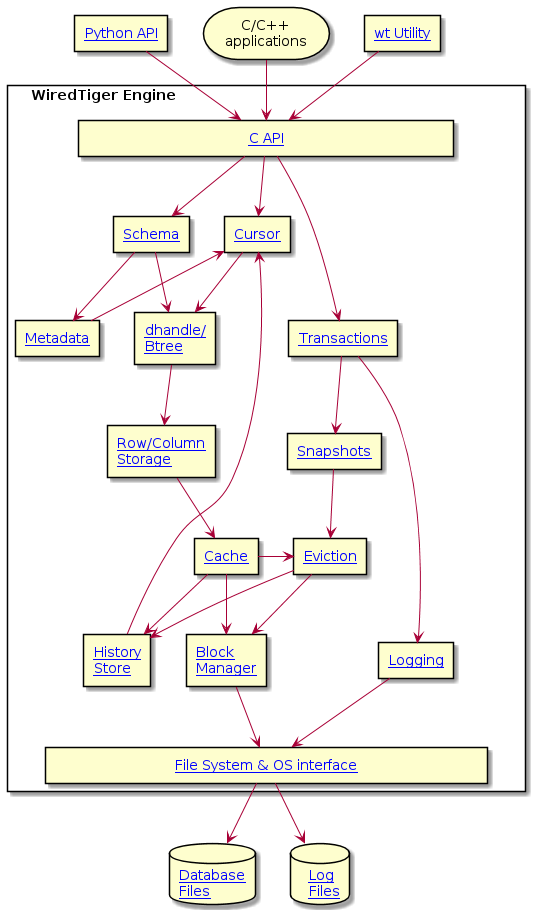 | Data Structures | Source Location |
|---|---|---|
| |
Caution: the Architecture Guide is not updated in lockstep with the code base and is not necessarily correct or complete for any specific release.
S3 storage source, or the S3 store, is a WiredTiger extension that implements the storage source abstraction for AWS's S3 object-store. The store extends the WiredTiger's capability to store the data files on the S3 cloud. The extension provides a means to construct, configure and control a custom file system linked to an S3 bucket. The extension internally uses the API provided by the AWS C++ SDK to interact with the S3 cloud.
The S3 store implements the following key functionalities defined by the storage source interface:
WT_FILE_SYSTEM implementation for a given bucket. The store requires a bucket and an access token to create the filesystem. The bucket is expected to be a string argument, which is the bucket name and the corresponding region separated by a ';', e.g. "bucket1;ap-southeast-2". AWS requires an access token to authenticate programmatic access to S3. The access token comprises of an access key ID and a secret access key as a set. The S3 store requires the token to be provided as a single string argument of the access key followed by the secret key, separated by a ';'.The S3Connection class represents an active connection to an S3 bucket. It encapsulates and implements all the operations the S3 filesystem requires. The instantiation of the class object authenticates with the AWS and validates the existence of and access to the configured bucket. The S3Connection exposes an API to list the bucket contents filtered by a directory and a prefix, check for an object's existence in the bucket, put an object to the cloud, and get the object from the cloud. Though not required for the file system's implementation, the class also provides the means to delete the objects to clean up artifacts from the internal unit testing.
WiredTiger supports a database over a custom file system by giving a WT_FILE_SYSTEM interface for the end-user to implement. The S3 store itself provides a means to configure as many file systems as needed, each linked to an S3 bucket. These file systems, called the S3_FILE_SYSTEM, are a custom implementation provided by the S3 store. The S3 filesystem contains an instance of the S3Connection class, hence providing an active connection to the S3 bucket embedded in the file system instance.
The S3 file system uses the functionality provided by the S3 connection to simulate a write-once-read-many file system. The filesystem can list the directory contents, check for a file's presence, and access the file by creating a filehandle. The files that are not in the cache are first downloaded from the bucket and put in the cache before a filehandle is made to access them.
The S3 store uses the filesystem's put-object functionality to flush the files into the cloud. The Tier Manager inside WiredTiger directs the flush of the files. The files pushed to the cloud are also copied to the local cache for easy access.
The S3 store also implements the WT_FILE_HANDLE interface, S3_FILE_HANDLE, to access the files on the S3 file system. When the handle is created, the local cache gets a copy of the S3 object if it doesn't already have it. That copy will be accessed by the handle. Since the local cache is a directory on the WiredTiger database's file system, the file is accessed using a WT_FILE_HANDLE implementation native to WiredTiger. Hence, a copy of native WT_FILE_HANDLE is kept encapsulated in the S3 filehandle. Since the object store is archival, all the write access methods are disabled.
The S3 store provides a logger implementation that redirects the generated logs to the WiredTiger logging streams. AWS SDK also registers the same logger, and the best attempt is made to match the SDK's logging levels to WiredTiger's.
Several statistics are also collected to count various interactions with S3 and the operations on the objects and files.