 |
Version 10.0.2
|
|
Version 10.0.2
|
 | Data Structures | Source Location |
|---|---|---|
| |
Caution: the Architecture Guide is not updated in lockstep with the code base and is not necessarily correct or complete for any specific release.
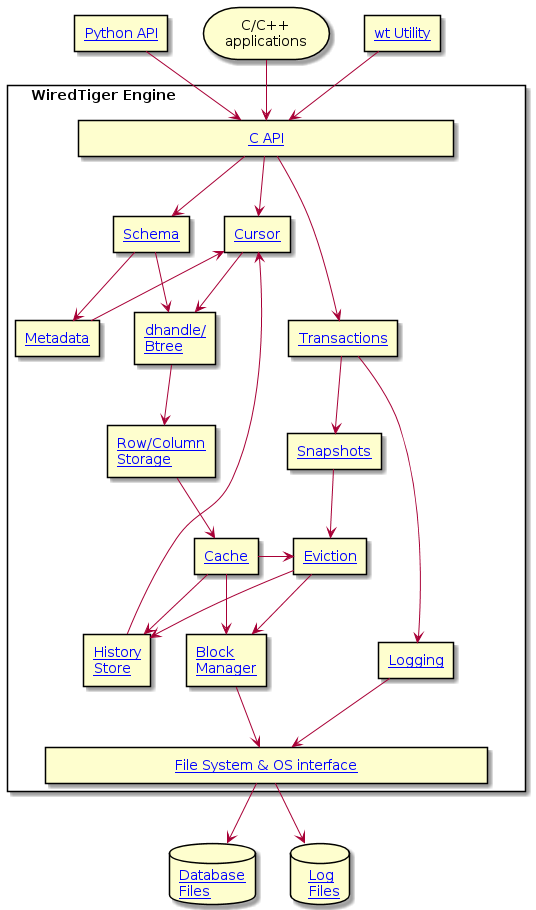
WiredTiger represents database tables using a B-Tree data structure (WT_BTREE in btree.h), which is made up of nodes that are page structures. The root and internal pages only store keys and references to other pages, while leaf pages store keys and values. Pages are populated with records as users insert data into the database. Records are maintained in sorted order according to their key, and pages will split once their configured limit is reached, causing the B-Tree to expand. Pages have an in-memory representation as well as an on-disk representation. The focus here will be on the in-memory representation of the B-Tree and its pages as defined in btmem.h. The on-disk representation is discussed in the Data File Format page.
As discussed in the Data Handles page, data handles (dhandles), are generic containers used to access various types of data sources. Dhandles that represent B-Trees contain a pointer to the WT_BTREE. At a high-level, the WT_BTREE contains a memory cache of key value pairs, along with functions to read and write data as needed to and from the data file. It also contains the specific WT_BTREE type, a reference to the root page on disk for access to the underlying data, and information used to maintain the B-Tree structure. The different B-Tree types support different access methods; row-store is most commonly used (WT_BTREE_ROW), and column-store is available with either fixed-length records (WT_BTREE_COL_FIX) or variable-length records (WT_BTREE_COL_VAR) (see Row Store and Column Store for more details).
B-Trees can grow to a very large size, and the space in memory is generally not large enough to hold all the pages of the B-Tree. To access a page in the B-Tree, we require a WT_REF which tracks whether the page has or has not been loaded from storage. Once the page is loaded, the WT_REF or reference structure will have a valid WT_PAGE pointer which represents the in-memory page. The WT_BTREE structure contains a WT_REF that points to the root page of the given tree. Other pages can be accessed as required by traversing through the child structures of the root page, and the child structures of those pages, and so on.
To insert or modify values in a row-store B-Tree, the code traverses down to the leaf pages which contain the key/value pairs (WT_ROW structure). New key/value pairs are inserted into row-store leaf pages using a WT_INSERT structure. Existing entries on leaf pages can be updated, modified or deleted through WT_UPDATE structures. As new updates are made, these structures are chained into an update list. This means that an entry may have some old values, or deleted values, which may be visible depending on the timestamp used by a reader.
Truncate allows multiple records in a specified range to be deleted in a single operation. It is much faster and more efficient than deleting each record individually. Fast-truncate is an optimization that WiredTiger makes internally; whole pages are marked as deleted without having to first instantiate the page in memory or inspect records individually. In situations where this is not possible, a slower truncate will walk keys individually, putting a tombstone onto each one to mark deletion. Truncation is also possible for log files but the focus here will be on truncation for B-Tree data files (file: uri).
To perform a truncate on a file, a start and stop cursor are positioned corresponding to the desired range provided by the user. The desired start and stop keys do not actually need to exist since the cursors are positioned by doing a search-near rather than a search. Once positioned, we do a page-by-page walk on the B-Tree, fast-truncating pages where possible. When a page is marked for fast-truncation, its WT_READ_TRUNCATE flag is set, and the code tries to delete the page without instantiating it into memory. If no errors are encountered, a page-deleted structure WT_PAGE_DELETED is allocated and initialized with the timestamp, transaction id and state information associated with the truncate. Finally, the page is published as deleted using the WT_REF_DELETED flag. Pages which are not eligible for fast truncation are pages where only part of it will be deleted (e.g. the first and last pages of the truncate range), pages with overflow items, or pages with prepared updates. These pages will have their records deleted individually.
Truncation differs from other operations in the sense that it does not have the same transactional semantics. If a range truncate is in progress and another transaction happens to insert a key into the same range, the behavior is not well-defined. A conflict may be detected, or both transaction may be permitted to commit. In the scenario that both commit, if the system crashes and recovery runs, the resulting state of the database may be different to what was in the cache had the crash not happened.
In some scenarios, a reader may want to read older values from a page from a point in time before the page got truncated. The page must first be re-instantiated into memory; the __wt_page_in_func (see bt_read.c) reads in a page from disk, and builds an in-memory version. Then as part of the page read process, we create a WT_UPDATE with a tombstone in the same transaction the truncate happened.