 |
Version 12.0.0
|
|
Version 12.0.0
|
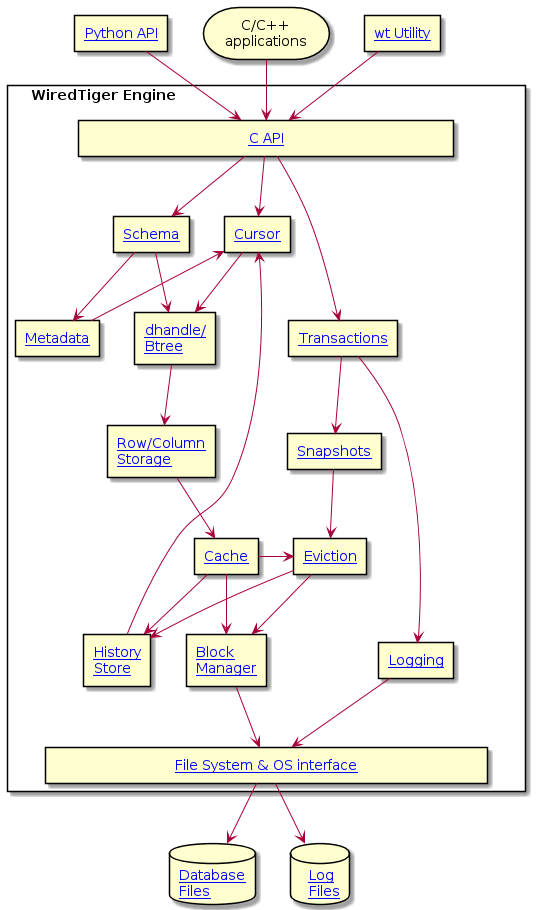 | Data Structures | Source Location |
|---|---|---|
| |
Caution: the Architecture Guide is not updated in lockstep with the code base and is not necessarily correct or complete for any specific release.
Compaction is a cooperative process between the Btree layer and the Block Manager to reduce the on-disk footprint of WT tables. The compaction process is initiated by the user application by calling WT_SESSION::compact method. Overall, the compaction process involves rewriting disk blocks from the end of the on-disk file to the start of the file, hence giving an opportunity to reclaim the space from the end of the file through truncation and effectively reducing the file system reported file size. Note that the compaction is a "best-effort" process and does not guarantee a reduction in file size.
Before understanding the compaction process, we need to understand how disk blocks are referenced by the checkpoints. Each checkpoint references a certain set of disk blocks for a table. When a dirty btree page is reconciled, a new disk block is assigned for the page and a new checkpoint starts referencing the new block used for the page. Once the checkpoint referencing the old block is deleted, the old disk block becomes available for reuse. The compaction process copies over the data from the blocks at the end of the file to the reusable blocks at the start of the file.
The compaction process starts with a system-wide checkpoint. There are potentially many dirty blocks in the cache, and the intention here is to write them out and then discard previous checkpoints so that there are as many blocks as possible on the file's "available for reuse" list when the compaction starts. The compaction logic then starts examining the files that need to be compacted. Compaction does not proceed if any of the following conditions are met:
free_space_target (see WT_SESSION::compact) worth of space can be theoretically recovered.Once enough free space is available, one of the two following hard-coded conditions must be met for compaction to proceed:
Depending on the scenario, compaction tries to move blocks from the last 20% or 10% of the file into the beginning of the file. The reason for this is because compaction walks the file in a logical order, not block offset order, and compaction of a file can fail if the block from the end of the file is not written first. Note that the block manager uses a first-fit block selection algorithm during compaction to maximize block movement. The process is repeated multiple times until the block manager detects that there are no blocks from the last 10% of the file that can be moved.
Diving deep into the compaction process, the btree layer walks the internal pages for a given table to identify leaf pages that can be rewritten. For each leaf page referenced by the internal page, we use a block manager API to assess whether it will be beneficial to rewrite the leaf page. If the block manager recognizes that rewriting the page will be beneficial, it rewrites the disk block to a new disk location. The new disk address is placed into the parent internal page and the page is marked dirty. In this way, the leaf page is rewritten without being brought into the cache. If the leaf page is already in the cache, the leaf page is simply marked dirty and the subsequent checkpoint or eviction rewrites the page. When a leaf page is rewritten by compaction, the parent internal page is marked dirty so that the chain of internal pages from root to the leaf page is rewritten by the next checkpoint or eviction.
After each compaction pass, two checkpoints are executed because the block manager checkpoints in two steps:
The blocks made available for reuse during a checkpoint are put on a special checkpoint-available list and only moved to the real available list after the metadata has been updated with the new checkpoint's information. For this reason, blocks allocated to write the checkpoint itself cannot be taken from the blocks made available by the checkpoint. To say it another way, the second checkpoint puts the blocks from the end of the file that were made available by compaction onto the checkpoint-available list, but then potentially writes the checkpoint itself at the end of the file, which would prevent any file truncation. When the metadata is updated for the second checkpoint, the blocks freed by compaction become available for the third checkpoint, so the third checkpoint's blocks are written towards the beginning of the file, and then the file can be truncated. It is worth noting that the usage of named checkpoints may prevent compaction from accomplishing anything as they are not discarded until explicitly removed or replaced.
Compaction is a time-consuming operation and therefore logs have been added in compaction logic to track current progress. Some of the verbose logs for compaction can be activated by setting "verbose=[compact,compact_progress]" configuration option for wiredtiger_open() method. Apart from verbose logs, WT also records statistics about compact progress that can be used to debug issues with the compaction process.
Background compaction is a WiredTiger service that runs compaction autonomously on all the eligible files present in the database while being the least disruptive as possible. Every file is eligible unless:
Background compaction retrieves the files to compact by walking the metadata file. To limit disruption, background compaction reduces the number of checkpoints by skipping the first one described in the section above. Furthermore, background compaction gathers statistics over time to keep track of tables where compaction is successful. Using those statistics, the service focuses on tables where compaction is likely to reclaim space and avoids unnecessary attempts. Finally, the thread makes sure that the following conditions are met before processing the next table:
eviction_dirty_trigger threshold and,eviction_trigger threshold.Background compaction can be enabled, configured, and disabled through the same API WT_SESSION::compact. When disabled, background compaction turns off as soon as possible and when re-enabled, it starts from the last processed table.